
Photo by: Samuel Zeller
Cześć, dzisiaj chciałbym skupić się na trochę innym temacie niż ostatnio. Pomówimy o bazach danych. A dokładniej o rozwiązaniu które dostarcza Azure, zwanym read scale-out replicas. Zanim jednak przejdę do meritum, chciałbym wam przestawić powód dla którego się tym zainteresowałem. Wszystko zaczęło się od naszego firmowego projektu. Jako że projekt już jakiś czas istnieje, pojawiła się naturalna potrzeba jego przyśpieszenia. Okazało się, w sumie jak często w tym wypadku, że wąskim gardłem naszego softu jest baza danych. Dokładniej to fakt że do odczytu i zapisu używamy jednej bazy. Jest to mocno problemowe, jeżeli system obsługuje generowanie miesięcznych raportów czy dość dużych faktur. Powoduje to dość duże obciążenie, co przekłada się na potrzebę mocnego skalowania bazy w górę. Co w konsekwencji zwiększone koszty jej utrzymania. Architektura naszego systemu zawiera w sobie CQRS. Dzięki temu, mamy pole manewru, które pozwoli nam na rozdział zapisu i odczytu. Stwierdziliśmy że można by było to w końcu domknąć, i ostatecznie rozdzielić to na dwie osobne bazy. Było parę pomysłów w jaki sposób wpiąć się w obecne rozwiązania aby móc to osiągnąć. Jednak fakt że projekt ciągnie się już jakiś czas i dużo dziwnych rzeczy zostało tam porobionych, mocno utrudniło sprawę. Na szczęście, trafiliśmy na to rozwiązanie dostarczone od Azure i dla nas wydaje się ono najszybsze do wprowadzenia, bez straty wydajności. Póki co jesteśmy na etapie testowania tego rozwiązania, ale mimo to chciałbym je trochę wam przybliżyć. Tak więc zapraszam do dalszej lektury :)
Read scale-out
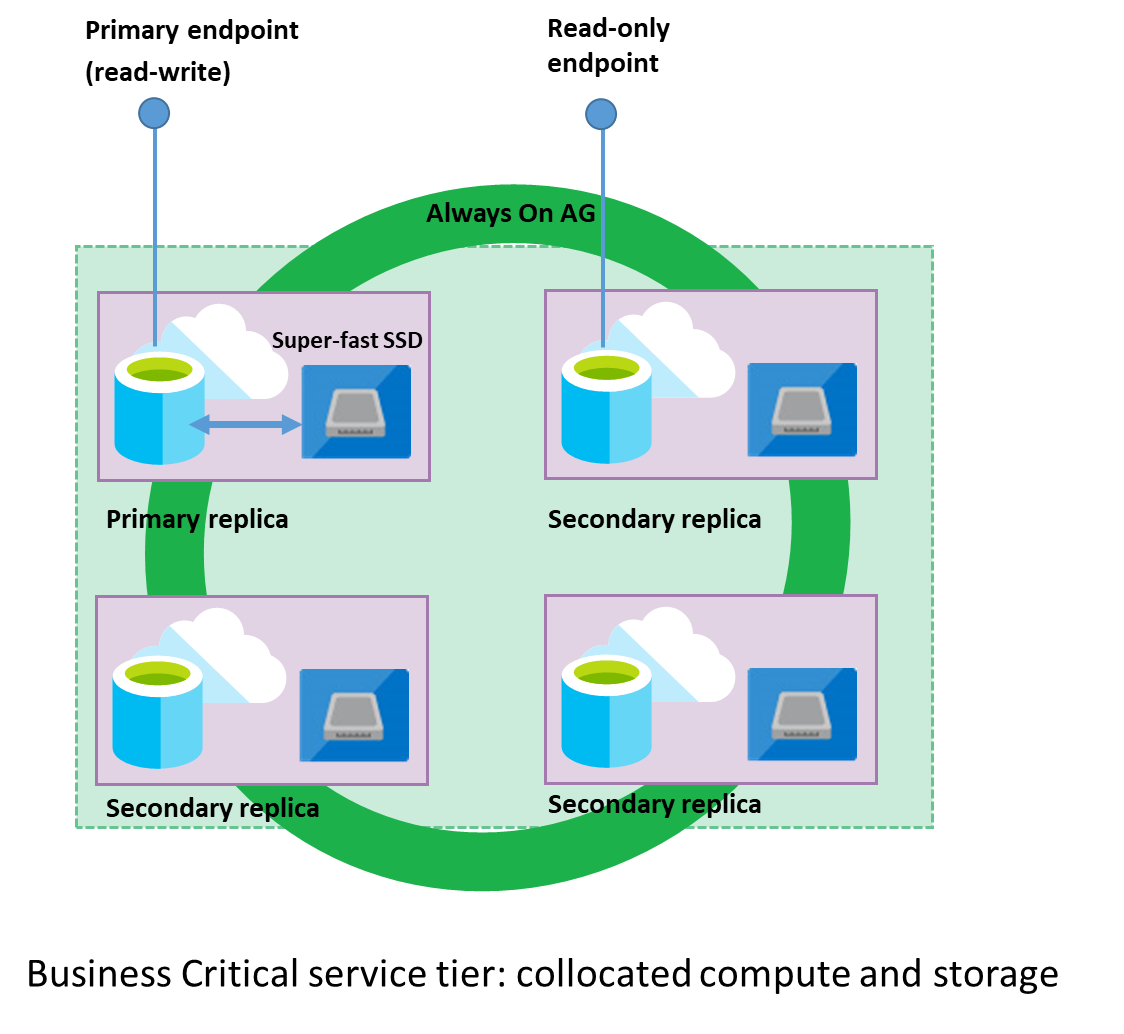
źródło obrazka: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-read-scale-out
Azure każdą bazę danych z warstwy Premium lub Business Critical zabezpiecza kilkoma replikami baz w trybie read-only w celu zapewnienia jak najwyższego poziomu dostępności SLA(99,9%). Co najważniejsze każda z replik znajduje się w tej samej warstwie cenowej tak samo jak główna baza read-write. Tak więc uzyskujemy dostęp do drugiej, tak samo szybkiej bazy, a do tego nie ponosimy dodatkowych kosztów. A pojawiłyby się one, gdybyśmy zdecydowali się na trzymanie dwóch baz obok siebie. Wcześniej dostęp do naszych replik nie był możliwy, nawet jeżeli baza miała włączoną funkcjonalność Always ON. Dopiero teraz z w trakcie tworzenia nowej bazy, lub na już istniejącej, możemy załączyć funkcjonalność Read Scale-Out aby uzyskać możliwość połączenia się z nimi. # Jak to włączyć i się połączyć?
Funkcjonalność tą możemy włączyć wykorzystując w tym celu PowerShella. Dla istniejących już baz wystarczy następujące polecenie:
Set-AzureRmSqlDatabase -ResourceGroupName <myresourcegroup> -ServerName <myserver> -DatabaseName <mydatabase> -ReadScale Enabled
Do którego przekazujemy nazwę resource group w której znajduje się nasza baza. Nazwę serwera jak i samej bazy. Ostatni parametr załącza funkcjonalność ReadScale. Chcąc stworzyć nową bazę danych wystarczy skorzystać z:
New-AzureRmSqlDatabase -ResourceGroupName <myresourcegroup> -ServerName <myserver> -DatabaseName <mydatabase> -ReadScale Enabled -Edition Premium
Następnie do naszego ConnectionStringa dodajemy parametr ApplicationIntent. Za pomocą niego definiujemy czy chcemy podłączyć się do bazy ReadWrite czy ReadOnly. Należy pamiętać, że domyślnie, jeżeli nie zdefiniujemy tego parametru, zawsze będziemy uderzać do bazy ReadWrite. Poniżej mały przykład jak to powinno wyglądać:
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<myPassword>;Trusted_Connection=False; Encrypt=True;
Spójność danych
Spójność danych, między bazami mamy zapewnioną na poziomie transakcji (transactionally consistent state), ale w różnym punkcie czasu. Z dokumentacji, wynika że opóźnienie może wystąpić, ale bardzo niewielkie. Dzieję się to z tego powodu, że replikacja danych wykonywana jest asynchronicznie. Niestety w żadnym rozwiązaniu nie da się go całkowicie wykluczyć i zawsze może się to okazać naszą piętą achillesową. Azure jednakże zaznacza że opóźnienie dla baz z tego samego regionu jest dosyć małe i rzadko występujące.
Podsumowanie
Póki co w środowisku developerskim nie zauważyłem żadnych problemów z połączeniem z każdą z baz, czy też spójności danych. W praktyce, gdy testowałem to rozwiązanie, nie udało mi się zauważyć rozbieżności w danych między bazami. Wszystko działało od strzała. Jednakże dopuszczamy możliwość małego rozjazdu, jednakże póki co, jeszcze się na niego nie natknąłem :) Na pewno dużą zaletą jest z duplikowanie DTU bazy, przy nie zwiększonych kosztach utrzymania bazy. Dodatkowo koszt wprowadzenia możliwości korzystania z dwóch baz, w zależności od architektury naszego systemu może opierać się tylko na wprowadzeniu w odpowiednim momencie zmiany connection stringa. W naszym przypadku jest to mocno zachęcające, gdyż w razie jakichkolwiek problemów, nie będzie problemem wyłączenie tej funkcjonalności. Także wprowadzenie jej nie będzie wymagało dużych nakładów czasu. Wydaje się być to ciekawym rozwiązaniem, o którym warto jest na pewno usłyszeć i już w swoim gronie rozważyć czy jest sens i możliwość z niego skorzystać.